您当前的位置:检测资讯 > 科研开发
嘉峪检测网 2024-05-10 11:15
近日,知名分析师郭明淇披露英伟达下一代AI芯片R系列/R100 AI芯片的相关信息。据他所说,该芯片将于2025年4季度进入量产,系统/机架解决方案可能会在2026年1H20开始量产。
在工艺方面,R100将采台积电的N3制程 (vs. B100采用台积电的N4P) 与CoWoS-L封装 (与B100相同)。与此同时,R100采用约4x reticle设计 (vs. B100的3.3x reticle设计)。
来到Interposer尺寸方面,按照郭明淇的说法,英伟达尚未定案,但会有2–3种选择。
至于备受关注的HBM方面,R100预计将搭配8颗HBM4。
同时,英伟达GR200的Grace CPU将采台积电的N3制程 (vs. GH200/GB200的CPU采用台积电N5)。
按照郭明淇所说,Nvidia已理解到AI服务器的耗能已成为CSP/Hyperscale采购与资料中心建置挑战,故R系列的芯片与系统方案,除提升AI算力外,耗能改善亦为设计重点。
英伟达芯片路线图,深度解读
2023年10月,英伟达更新了其最新数据中心路线图,其激进的更新幅度更新了所有人。首先,我们先回顾一下英伟达过去几年的路线图。以下是2021年 4 月举行的 GTC 2021 上发布的内容:
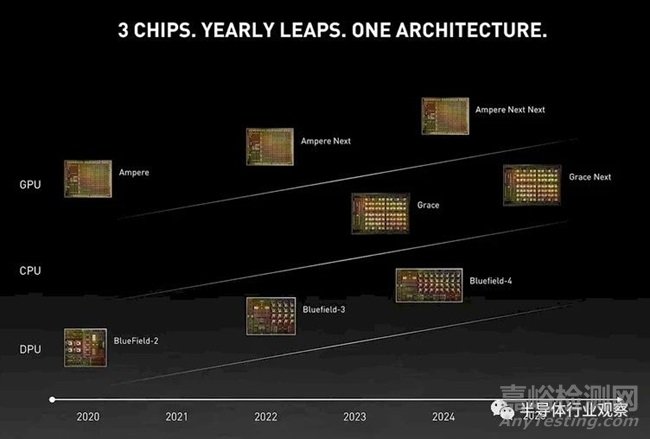
这是“Hopper”之后的更新版,在上面的路线图中被称为“Ampere Next”,在 2022 年 Computex 上发布:
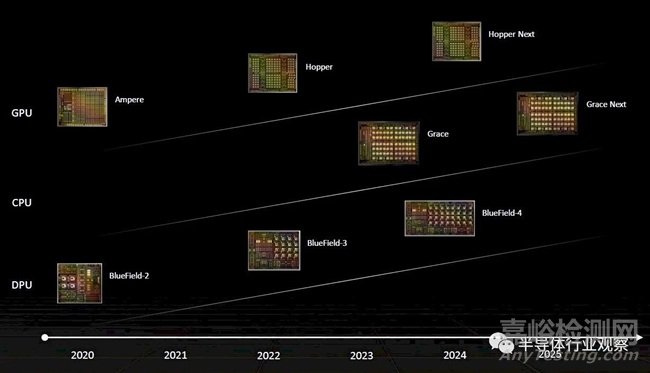
以下是我们认为今年早些时候发布的路线图的更新,其中添加了用于人工智能推理、可视化和元宇宙处理卡的“Lovelace”GPU 系列:
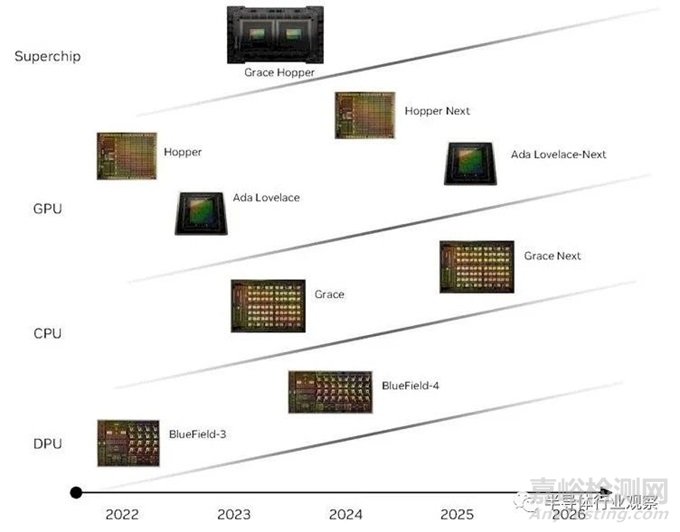
最后,这是英伟达近来发布的路线图,由semianalysis首先披露。
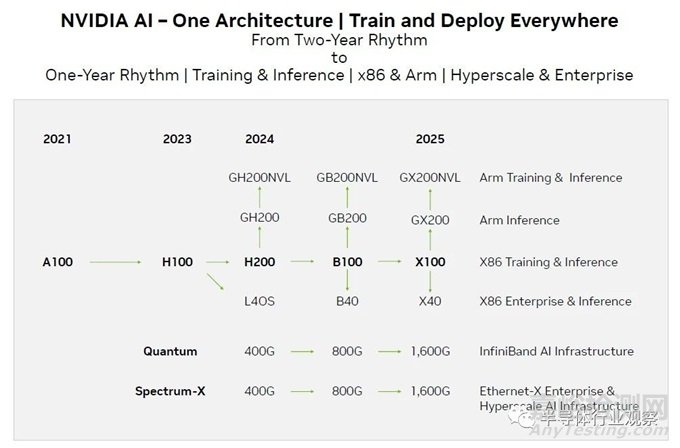
如果过去的趋势是未来趋势的指标——当芯片制造商向其超大规模和云构建商客户承诺两年推出一次的节奏时,它们肯定应该是未来趋势的指标,就像英伟达几年前所做的那样——那么我们绝对期待新架构的 Blackwell GB100 GPU 加速器将于明年 3 月至 5 月左右推出。但正如您在下面所看到的,Nvidia 主要 GPU 发布的节奏通常不到两年。所以这是一种回归形式。
以下是数据中心 GPU 在过去 21 年中的推出方式,数据中心 GPU 计算至关重要:
“Kepler”K10 和 K20,2012 年 5 月
“Kepler”K40,2013 年 5 月
“Kepler”K80,单卡上有两个 GK210B GPU
“Maxwell”M40,2015 年 11 月,主要用于 AI 推理,并非真正用于 HPC 或 AI 训练
“Pascal”GP100,2016 年 4 月
“Volta”GV100,2017 年 5 月(原始 Pascal 的某些功能直到 Volta 才出现)
“Ampere”GA100,2020 年 5 月
“Hopper”GH100,2022 年 3 月
“Hopper-Next”H200,2024年春季?
“Blackwell”GB100,2024年夏季还是秋季?
“Xavier”GX100,2025年春夏
我们很清楚,Hopper-Next 应该是 Blackwell GB100 GPU,而现在路线图上的 GH200 是一种权宜之计,试图转移人们对 AMD看起来将于 12 月推出的CPU-GPU 混合设备“Antares” Instinct MI300X GPU 和 MI300A 混合显卡的注意力。AMD 将在这些设备上拥有 HBM 内存容量和带宽优势,以及用于 CPU 和 GPU 的聚合内存,而 Nvidia 不能告诉所有人 H100NVL双倍卡就是答案。
因此,有两种方法可以使用即将推出的 Hopper-Next H200 GPU。我们赞成但仅基于预感的一个是 Nvidia 测试将两个 Hopper GH100 GPU 放入一个插槽中 ,因为它已经使用其 Arm 服务器 CPU 与其 Grace-Grace 超级芯片配合使用。我们在一年半前建议它这样做。该芯片的性能可以稍微降低,以获得更合适的功率范围,并留出空间来容纳更高的 HBM3e 内存堆栈,从而提高目前数据中心非常缺乏的内存与计算比率。
GPU 插槽中的芯片数量并不像每个插槽中的带宽那么重要。每个插槽需要两个 GPU,但内存带宽需要四倍、六倍或八倍才能真正领先并提高 GPU 的性能。我们半开玩笑地说:拥有一半 Hopper GPU 可能更有意义——称之为 Hop?– 如果您确实想提高 AI 工作负载的性能,则需要 2 倍的内存容量和 2 倍的内存带宽。
有些人认为H200只是内存升级,在相同的GH100 GPU上提供2倍的内存容量和2倍的内存带宽。我们认为会对它进行一些调整,并且可能会进行更深层次的垃圾分类,以至少提高性能。
这个路线图中还有另一件令人烦恼的事情:根据 Nvidia 的最新路线图,未来的 Blackwell GB100 GPU 和 B100 加速器到底什么时候出现?你看到上面有日期吗?我们推测是在 2024 年末,但 Blackwell 仍有一定的余地可以推迟到 2025 年初。(我们认为 Blackwell 芯片很可能以伊丽莎白·布莱克威尔 (Elizabeth Blackwell) 命名,她是第一位获得医学学位的女性在美国(在纽约州北部的日内瓦医学院,现在是雪城大学的一部分),也是第一位在英国总医学委员会医学登记册上登记的女性。)
无论如何,Blackwell GB100 GPU 都非常接近 GX100 GPU(我们将其代号为“Xavier”),预计将于 2025 年推出,我们认为是在今年晚些时候,但也可能不是。(除了漫威超级英雄宇宙中虚构的Charles Xavier 之外,我们找不到姓氏以 X 结尾的重要著名科学家,是的,我们知道 Nvidia 已经在其嵌入式系统之一中使用了该代号.“X”可能只是意味着它是一个变量,而 Nvidia 尚未决定有一个代号。)
我们认为 Nvidia 需要更多时间来调整 Blackwell 的 GPU 架构,并且考虑到 AI 模型变化的速度,如果事情很重要,例如 Volta 的 Tensor Cores 或稀疏性,Nvidia 应该这样做是合理且正确的支持是针对 Ampere,或者 Transformation Engine 和 FP8 是针对 Hopper。
解决这个问题后,我们对当前的 Nvidia 路线图有一些需要挑选的地方。例如,BlueField DPU 发生了什么?
DPU 是 Nvidia 硬件堆栈不可或缺的一部分,提供网络、安全和虚拟化卸载,并将超级计算机转变为多租户云。Hopper GPU 是在 2022 年 3 月的春季 GTC 会议上宣布的,而不是在 2023 年,并且也在 2022 年末发货。H100 NVL 和 Lovelace L40 失踪了。“Ampere”A100 于 2020 年问世,而不是 2021 年。Quantum 2 400 Gb/秒 InfiniBand 和 400 Gb/秒 Spectrum-3 以太网于 2021 年发布,并于 2022 年(而不是 2023 年)开始发货。速度为 800 Gb/秒以太网和 InfiniBand 的运行速度比我们在 2020 年 11 月与 Nvidia 交谈时的预期晚了大约一年。顺便说一句,上一代 200 Gb/秒 Quantum InfiniBand 于 2016 年发布,并于 2017 年发货。那里存在很大的差距,因为所有试图推销从 200 Gb/秒到 400 Gb/秒的跳跃的公司都存在这个差距。
鉴于这一切,我们更新了 Nvidia 官方路线图:

显然,生成式人工智能的爆炸式增长消除了数据中心和超级计算高层对计算和互连的犹豫。因此,每年一次的节奏是有意义的。但如果不出现一些滑点,可能很难维持。事实上,这个路线图可以被视为弥补 Blackwell 架构交付延迟的一种方式,而 Xavier GX100 将于 2025 年推出(也许非常接近 Blackwell)这一事实告诉您,事情已经发生了。也许 Nvidia 会从 Blackwell 开始,转向秋季发布和交付其数据中心 GPU?无论 H200 GPU 加速器是什么,值得注意的是没有 B200 或 X200 紧随其后。这款 H200 是一匹只会耍花招的小马。好吧,除非英伟达陷入另一个困境。。。。
这里有一些需要考虑的事情:当产品的需求是您可以交付的产品的 3 倍、4 倍、甚至 5 倍时,路线图的节奏并不重要,而供应量更重要。如果云和一些人工智能初创公司获得了所有 Hopper GPU,而其他人都无法获得,那又怎样呢?这意味着任何拥有矩阵数学引擎和人工智能框架的人都有机会出售他们得到的任何东西。
因此,我们看到这种情况正在发生,即使是像英特尔备受推崇的 Gaudi 加速器系列这样的死胡同产品。是的,Gaudi 2 可以与 Nvidia A100 甚至 H100 抗衡,是的,Gaudi 3 即将推出,其性能将提高 2 倍,但那又怎样呢?没有 Gaudi 4,但有一个名为“Falcon Shores”的 GPU,具有 Gaudi 矩阵数学单元和 Gaudi 以太网互连。在正常情况下,没有人会购买 Gaudi 2。但在生成式 AI 淘金热中,你可以获得的任何矩阵数学单元都必须这样做。
细研究了这个路线图后,这也许是最重要的事情。Nvidia 拥有大量现金来垄断 HBM 内存和 CoWoS 基板市场,并远远领先于也需要这些组件来构建加速器的竞争对手。它可以使用即将推出的组件,例如台积电非常有趣的 CoWoS-L 封装技术,该技术允许对小芯片进行相对正常的基板封装,但在小芯片之间设置小型中介层,需要大量电线来驱动高电压。这些小芯片各部分之间的带宽。(CoWoS-L 有点像英特尔的 EMIB。)如果愿意的话,它有足够的现金来制造两芯片 H200 和四芯片 B100。Nvidia 已经证明了四 GPU 设计的可行性,但公平地说,MI300X 表明 AMD 可以通过在巨大的 L3 缓存之上堆叠八个小芯片来做到这一点。
Nvidia 最好不要乱搞,因为在硬件方面,AMD 绝对不会。那些热爱开源框架和模型的人正在密切关注 PyTorch 2.0 框架和 LLaMA 2 大型语言模型,由于Meta开明的利己主义,它们没有任何障碍。PyTorch 显然在 AMD 处理器上运行得很好,我们认为在 MI300A 和 MI300X 上会做得更好。
因此,从 2024 年开始,Nvidia 芯片的步伐确实加快了每年升级的节奏。
请记住,你可以建造一条护城河,但当井干涸时你就不能喝它,因为水很臭,可能来自敌人的尸体
最后,我们来回顾一下semianalysis当时是怎么说的。
B100,上市时间高于一切
我们相信 Nvidia 的 B100 将在 2024 年第三季度大批量发货,并在 2024 年第二季度提供一些早期样品。从我们听到的性能和总体拥有成本来看,它击败了 Amazon Trainium2、Google TPUv5、AMD MI300X、Intel Gaudi 3 和 Microsoft Athena ,即使考虑到从设计合作伙伴/AMD/台积电购买这些芯片所支付的利润要低得多。
我们的理解是,与最初的“计划”相比,Nvidia 做出了多项妥协,以便将 B100 更快推向市场。例如,Nvidia 希望将功耗设定为更高水平 1,000W,但他们最初会坚持使用 H100 的 700W。这使得 Nvidia 在 B100 变体上市时能够坚持使用空气冷却。
Nvidia 最初也坚持在 B100 上使用 PCIe 5.0。5.0 和 700W 的组合意味着它可以直接插入 H100 的现有 HGX 服务器中,从而大大提高供应链更早提高产量和出货量的能力。决定坚持使用 5.0 的部分原因是 AMD 和英特尔在 PCIe 6.0 集成方面远远落后。Nvidia 自己的内部团队也没有准备好使用 PCIe 6.0 CPU,此外他们会使用更快的 C2C 样式链接。
ConnectX-8 稍后配备了集成 PCIe 6.0 交换机,但还没有人为此做好准备。我们的理解是,Broadcom 和 Astera Labs 只会在今年年底为 PCIe 6.0 重定时器做好批量出货的准备,并且考虑到这些基板的尺寸,仍然需要许多重定时器。这意味着最初的 B100 将限制为 3.2T,而 ConnectX-7 则限制为 400G,而不是 Nvidia 幻灯片声称的每 GPU 800G。保持空气冷却、电源、PCIe 和网络速度相同,使其非常易于制造/部署。
稍后Nvidia将推出1000W版本,需要水冷。这个变体出现得稍晚一些,并且将通过 ConnectX-8 实现每 GPU 网络的完整 800G。这些 SerDes 对于以太网/InfiniBand 仍然是 8x100G。虽然每个 GPU 的网络速度翻倍,但基数减半,因为它们仍然必须经过相同的 51.2T 交换机。B100 一代将不存在 102.4T 交换机。
有趣的是,我们听说 Nvidia 正在转向 B100 上的 224G SerDes NVLink 组件,如果他们能让它发挥作用,那就太棒了。与我们交谈过的大多数人都认为 224G 不可靠,并且不可能在 2024 年实现,除了 Nvidia 的人。我们不知道,但他们很可能在 2024 年坚持使用 112G,但我们目前倾向于 Nvidia 采取激进的态度。请注意,Google、Meta 和 Amazon 拥有 224G 的 AI 加速器,目标是 2026/2027 年以上量产,而不是像 Nvidia 那样 2024/2025 年。Nvidia 将击败他们的竞争对手。
我们听说这款 GPU 仍然是台积电的 N4P,而不是基于 3nm 的工艺技术。考虑到台积电的 3nm 对于如此大的芯片尺寸来说还不成熟,这是有道理的。根据其基板供应商 Ibiden 传闻的基板尺寸,Nvidia 似乎已转向具有 8 或 12 个 HBM 堆栈的 2 个单片大型芯片 MCM。这与 SambaNova 和英特尔明年的芯片类似的宏观设计。

Nvidia 没有像 AMD 那样使用任何疯狂的hybrid bonding,因为他们需要出货非常大的容量,而成本是他们的一个大问题。我们相信这两种 B100 变体将具有与 MI300X 相似或更多的内存容量以及更多的内存带宽。风冷 B100 可以有 6.4Gbps 堆栈,但水冷版本可以高达 9.2Gbps。
Nvidia还展示了GB200和B40。G 代表 GB200 和 GX200,因此它显然是一个占位符,因为 Nvidia 将推出新的基于 Arm 的 CPU。他们不会继续使用 Grace 这么久。我们认为 B40 是 B100 的一半,只有 1 个单片 N4P 芯片和多达 4 或 6 个 HBM 堆栈。与 L40S 不同,这对于较小模型的推断是有意义的。
X100,致命一击
最值得注意的是 Nvidia 的“X100”时间表。该时间表将与 AMD 目前的 MI400 时间表相匹配。AMD MI300X 的策略是在 H100 推出一年后推出。AMD 希望通过在技术上积极进取,MI300X 在一个令人印象深刻的封装中填充更多的计算和内存,与一年前的 H100 相比,可以在纯硬件上超越 Nvidia。
Nvidia 发现,他们的 2 年数据中心 GPU 产品节奏可以为竞争对手打开一扇窗口,试图利用更新的芯片在市场上站稳脚跟。现在,英伟达正在通过将产品节奏加快到每年一次来关闭这一窗口。“X100”预计于 2025 年推出,仅比 B100 晚一年。
鉴于这款 GPU 距离流片还很远,与 B100 不同的是,B100 已经已经Tape out了,事情仍然悬而未决。英伟达从未讨论过下一代之后的问题,所以这是史无前例的。
这个名字也显然不是“X100”。Nvidia 一直以 Ada Lovelace、Grace Hopper 和 Elizabeth Blackwell 等杰出女科学家的名字来命名他们的 GPU 代号。对于X来说,唯一符合逻辑的人就是研究半导体和金属能带结构的中国女性科学家谢希德。不过,,我们对此表示高度怀疑,尽管这可能是英伟达计划在下周传闻出口限制后再次向中国出售 GPU 的方式。
抛开笑话不谈,这个“规格”不值得猜测,因为网表甚至还没有完成。唯一有交集的是台积电的N3X的使用。

来源:Internet


