您当前的位置:检测资讯 > 科研开发
嘉峪检测网 2022-06-18 04:53
摘 要 / Abstract
临床研究中电子病例报告表(eCRF)的数据收集,传统上由临床研究协调员(CRC)阅读电子病历(EMR)数据将相关内容手动录入至电子数据采集(EDC)系统。为了减轻CRC的负担,目前已有研究在探索将EMR源数据经过数据标准化转换直接变为研究数据集的方法。EMR中大量的非结构化文本数据导致了数据提取困难,无法直接用于临床研究。本文首先探讨了国内对于真实世界数据应用于临床研究数据标准化的需求及困难,开发了一种数据标准化方法。本方法可以基于EMR源数据,通过数据标准化的方式自动填充临床数据交换标准协会(CDISC)标准的eCRF,并满足监管部门的数据递交要求。本方法采用了我国常见的数据标准、人工智能领域的自然语言处理技术,以及提升数据质量的创新型数据采集模式。其数据转化过程的核心是根据最简化的数据模型制定文本数据标签指南,提高了使用自然语言处理算法的效率,优化了其与临床数据模型的互操作性,以及辅助提取研究中所需要的标准术语库。
For the data collection of electronic case report form (eCRF) in clinical research,the clinical research coordinator (CRC) traditionally reads the electronic medical record (EMR) and manually enters its relevant contents into the electronic data collection system (EDC).In order to reduce the burden of CRC,methods has been explored to directly transform EMR source data into a research dataset through data standardization and transformation.The large amount of unstructured text data in EMR leads to difficulty in data extraction,which prevents data from being directly used in clinical research.This study discusses the domestic needs and difficulties of real-world data standardization,and develops a data standardization framework to solve the difficulties.The data standardization framework developed can be used to automatically fill the eCRFs based on the CDISC standard using EMR source data while satisfying regulatory requirements for data submission authorities.The framework considers China's common data standards,natural language processing technology in the field of artificial intelligence,and innovative data acquisition mode to improve data quality.The core aspects of the data transformation process in the standardization framework include the formulation of text data label guidelines according to the simple data models,improvement of the efficiency of natural language processing algorithms,optimization of interoperability with clinical data models and capture of standard terminologies used in clinical research.
关 键 词 / Key words
真实世界数据;临床研究源数据采集;数据标准化; 电子源数据;符合监管提交标准
real-world data; collection of clinical research source data; data standardization; electronic source data; compliace with regulatory submission standard
01、研究背景
真实世界数据(real-world data,RWD)是指来源于日常收集的各种与患者健康状况和(或)诊疗及保健有关的数据[1-5]。目前,在我国与真实世界数据源[如电子病历(electronic medical records,EMR)数据]相关的数据标准已逐渐从临床文档的基本指南演变为更为通用的临床数据模型。如果不从根本上改进阅读EMR的功能、提高临床诊疗的质量,对EMR进行数据标准化将毫无意义。因此,实施真实世界数据标准,通常是使用更标准化的数据收集方法的综合讨论结果。该方法首先要在满足常规临床诊疗数据收集要求的基础上,通过提高数据收集的质量,更好地利用真实世界数据,例如将其用于临床研究和临床决策支持。
2009年12月,原卫生部、国家中医药管理局发布《电子病历基本架构与数据标准(试行)》[6],考虑到中西医结合的病历书写基本规范和现有EMR的信息主要来源,采用目前卫生领域已有的国际、国内普遍应用的成熟标准,构建适用于满足医疗卫生机构间临床诊疗信息共享的数据集以及共享文档标准,推广及评价数据标准的实际应用。2018年,国家卫生健康委办公厅发布《电子病历系统应用水平分级评价标准(试行)》[7]并实施评价医院系统的分级,促使各医院均加强了医院系统功能。政策发布的目的是为使2020年所有3级医院达到分级评价4级以上(全院信息共享、初级医疗决策支持);2级医院达到分级评价3级以上(部门间数据交换)。目前,多数医院信息系统已拥有基础的全院信息共享能力。2020年8月,国家卫生健康委统计信息中心发布了《国家医疗健康信息医院信息互联互通标准化成熟度测评方案(2020年版)》[8],更详细地评价了医院平台互联互通标准化成熟度。互联互通的评价标准,以提到的EMR数据集标准转化成HL7 临床文档结构(CDA)标准的电子病例共享文档标准为主,而HL7 CDA是以HL7 RIM作为主要支撑的数据模型[9-10]。
如果EMR数据变得标准化且更容易获取,临床研究的未来将受益匪浅。然而,由于完全通过使用标准化数据元素收集数据存在一定局限性,为了充分利用EMR,需要考虑结构化和非结构化数据。标准化数据元素的使用应限于特定的用例,例如只是汇总住院患者主页的患者病例报告,而不是扩展到所有数据元素。且标准化数据元素不适合医生在临床诊疗期间描述其完整的思维过程,通常缺乏医生文本汇录所需要的细节颗粒度以及临床判断中的推理过程。一般来说,通过使用越来越具体的数据元素或特定的词汇进行标准化,将减少用于描述医疗活动的思维范围,并增加选择正确选项所需的人力成本。因此,标准化数据的工作最好由能够更快地适应新数据模型和标准词汇表的算法来处理,而不是对生成源数据的人员进行过多培训。
如何提高从文本记录中提取临床研究数据的能力,将可能是未来数据标准化的潜在研究热点。①与基于系统改变整个数据结构的更改相比,改进文本输入的建议更容易实施。②将数据模型约束从源数据结构中分离出来可能会激发更简单的数据建模方法,而不必采用通用数据模型,如观察健康数据科学和信息学OMOP通用数据模型(OMOP CDM)。构建包含所有类型研究模型所付出的努力,将可能因无法实施和审核这些模型情况而失败,或导致使用算法提取所需数据的效率低下。因此,模型就像术语一样,需要具备关注并适应不同研究项目的能力。③可以更有效地捕获新的思维过程或常用的医学术语,并用于快速改进现有的数据模型和术语库。④自然语言处理(nature language processing,NLP)算法正在迅速发展,与人工相比,其可以更快地提取数据和数据上下文关系。本文旨在探索临床研究中非结构化文本数据的电子来源(eSource)模式,并将开发一个从真实世界数据到临床研究数据的标准化方法,用于根据临床数据交换标准协会(CDISC)标准填写病例报告表,并满足数据收集中的监管和可追溯性要求。框架中应用了我国常见的数据标准、人工智能领域的自然语言处理技术,以及提升数据质量的创新型数据采集模式。
02、从真实世界数据到临床研究数据标准转化过程的概述
将真实世界数据用于临床研究,理想的方案是能直接从医疗机构中的EMR捕获源数据并将其传输到临床研究电子病例报告表(electronic case report form,eCRF)的过程,真正实现电子数据采集 (electronic data capture,EDC)系统。即需要研发一种能根据临床研究方案中有关研究数据采集要求,在真实医疗环境中完成电子源数据记录(eSource record,ESR)的工具。其功能涵盖临床研究全流程,主要包括了源数据采集、数据提取和治理以及EDC和EMR对接。临床医师根据研究方案制定符合临床习惯的病历书写规则,通过语音输入和病史问诊的病历预填充等功能可以更高效地完成病历记录,利用微信公众号等院外随访功能可以方便地收集院外数据。ESR可以实时自动从完成的病历中抓取数据填充到eCRF中,同时也支持对源数据进行溯源查看。ESR充分考虑了源数据来源的多样性、数据互操作性和数据标准化的挑战。通过创新性地优化临床研究的源数据采集过程,并遵循电子源数据要求理念和药物临床试验质量管理规范(GCP)原则设计,ESR系统还应满足临床研究数据质量标准(ALCOA+CCEA 原则),同时提高临床医师撰写EMR的工作效率。通过对接EMR和EDC,ESR可以灵活应对当前医疗信息水平现状,实施更简单且易于落地推广,具有更高的规范性和可持续性。为了更好地将真实世界数据应用于临床研究,ESR系统必须与EMR和EDC系统具有互操作性,并满足有关数据可追溯性的法规要求[11]。
为加强系统之间的互操作性,在ESR系统内部设置了面向不同临床研究角色的工作界面。医生可以选择使用各自医院的EMR系统,或直接使用ESR系统内的电子病历记录模板,即ESR和EMR。此时,若医生希望将数据导出至各自的EMR系统,ESR系统也可实现回传标准化后的EMR文件。
此外,ESR系统还考虑了临床研究开展过程中临床研究协调员(clinical research coordinator,CRC)记录CRF的工作。ESR系统能够从EDC系统中检索CDISC操作数据模型(CDISC ODM)表单并直接展示源数据。在数据标准化的过程完成后,CRC能够审核单个表格的预填数据是否正确,并在签署确认后将CRF发至EDC系统。这样,数据的可追溯性即可通过ESR系统得到保证,因为其记录了整个数据标准化过程的轨迹,并能辅助CRC对每个CRF字段在原始文本里的记录进行溯源。从真实世界数据到临床研究数据的标准化流程如图1所示,通过对原始文本进行分割和标准化,最终生成临床研究数据集。
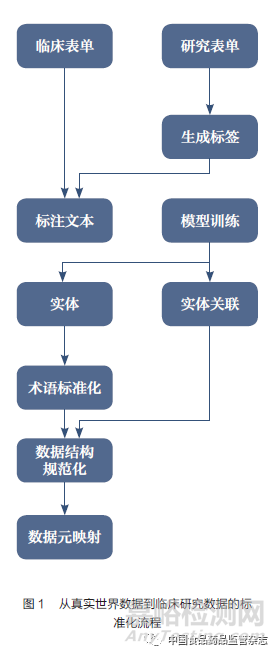
03、从真实世界数据到临床研究数据标准转化过程的实施
3.1 EDC和EMR分别发送CRF和患者临床表单至ESR系统
eSource流程主要涉及3个系统:EMR、ESR和EDC系统。EDC系统以CDISC ODM文件的形式传送研究数据集和数据格式的要求,EMR系统则提供所需的患者电子病历。ESR系统的EMR方将负责电子病历的注释,而ESR系统的EDC方将负责填写CRF并生成可追溯的源数据以便CRC审核。
申办方首先通过EDC系统将CRF以文件形式发送至ESR系统,该文件可在ESR系统中呈现。一旦有患者入组,EMR系统可将受试者在研究开始后的所有电子病历发送至ESR系统。
3.2 研究数据集的建模及标签生成
建模前须充分了解研究数据集的变量类型及其特征,之后才能同时对研究数据集中每个变量的域及属性进行建模。通常,多个CDISC域可以在更高水平进行合并,且这些域往往包含相同的属性。
建模的第1步是使用类似于比OMOP CDM的定义更为广泛的标准,包括医疗状况发生 (condition occurrence)、操作发生(procedure occurrence)、药物暴露(exposure occurrence)等,相当于对分类更为详细的CDISC域进行了整合[12]。目的是提高标签的提取效率。
第2步是将属性与域分开建模,属性的建模不受域的限制,以避免出现重复使用同一属性描述不同域的现象,减少标签数量。本研究属性是在临床数据获取标准(CDASH)数据元素的类型指导下进行建模。例如手术用药(AG)和伴随用药(CM)中的剂量和频率(DOSFRQ)在CDASH中建模为AG.DOSFRQ和CM.DOSFRQ,属性DOSFRQ是公共属性,将成为通用数据元素(common data elements,CDE)的属性标签。
第3步是标记并提取章节标题,以明确文本的基本结构。目前,我国的EMR还未能普及HL7 CDA类标准文档,最主要的原因是EMR很多都是由非结构化的没有明确文本分段的文本数据组成。如果不对章节进行结构化,数据可能会丢失重要的背景信息,最终导致标签错误、数据质量下降。
3.3 模型训练和实体及实体间关系的提取
医学专家和研究人员根据建模中使用的标签编写了标签指南。标签也可以称为实体。标签注释工作人员由2名接受过专业训练的研究人员组成,使用编写好的标签指南对EMR进行注释,包括每个域名标签(如药物名称)、属性标签(如剂量和频率),以及域名称与属性之间的实体关系。域名称与属性之间的实体关系仅限制单向关系,如从域名至属性或是从域名到其他域名称,实体之间不能使用双向链接。使用标签、标签位置和标签之间的关系训练NLP模型。快速标记方法是通过反复进行以下操作:①标记总样本量的10%;②用样本训练NLP模型;③预先标注下一个10%的数据并进行人工修改。当NLP模型被认为足够精准时迭代过程停止,可以将模型应用在剩余的数据提取中。
在实体抽取方面,采用双向变形编码器(BERT)+双向长短期记忆神经网络(BILSTM)+条件随机场(CRF)的命名实体识别(named entity recognition model)[13]。实体关系抽取方面,采用生物医学文本挖掘的双向变形编码器(BIO-BERT)的关系抽取模型,监督式学习(supervised learning),并使用标注的实体关系进行模型优化[14]。
3.4 生成研究专用术语库
研究专用术语库是指标签中实际提取得到的术语和标准术语之间的映射库。建立专病领域研究专用术语库,能够同时满足相关领域内其他研究的术语标准化需求。建立研究专用术语库需要有提取到的标签、CDISC ODM特定术语表(code list)以及国际标准术语[如《国际疾病分类》(第10版)(ICD-10)]。
首先将标签中的提取术语和CDISC代码值整合并进行匹配。术语匹配是通过将通用标准术语库(如ICD-10)使用Opaki BM25的推荐算法算出每个术语中单词的分数、然后使用提取术语作为搜索术语、找到分数最高的标准术语[15]。匹配完成后,每个标准术语将作为一个组,每个单独的组将由医学专家在术语编辑工具内审核,对于标准术语匹配错误的标签提取术语,需要人工手动重新分配标准术语[16]。研究专用术语库最终将生成一个词汇表,包括了标签、标准提取术语、标准术语代码、标准术语代码系统、原始术语、原始术语代码和原始术语代码系统,允许存储可用于填写CRF的预先指定CDISC代码和值。对于标签不是文本类型的数据,例如日期或数值标签,将会制定单独的表格用于记录每个标签所需的标准数据格式,这些格式由CDISC ODM文件预先指定或根据数据类型自动分配。
3.5 实体提取后,在填充CRF之前的规范化规则
NLP模型的输出主要有2个表,即所有提取出的标签值列表(实体表)和实体之间的关系列表(实体关系表)。
第1项任务是使用特定研究术语库,将每个实体标签标记标准值和标准标签类型。实体表的数据元素,包括实体ID、实体值、实体值存在文本段的位置,实体标签类型、实体标准代码、实体标准值、标准标签类型和跟踪数据。跟踪数据包括患者ID、医疗报告ID、文本段ID和记录日期。
第2项任务是将实体关系表转换为基于域的单条记录。先将关系表转换为各自的数据篮,每个数据篮都须指定数据篮ID和主实体ID。数据篮仅限于实体间的一阶关系,这意味着如果存在实体A→实体B→实体C的关系,数据篮将只包括实体A→实体B,以防止数据篮中存在复杂的嵌套关系。可能会存在一种包含多个主实体的数据篮的情况,原因是其中1个主实体是另1个主实体的适应症,例如1个疾病名称是药物名称实体的适应症(图2)。相应的方法是将对所有主实体预先做网络分析(network analysis)、将对于存在关系的主实体,标注相应的主实体链接ID,并将这种关系添加到实体关系表中。

第3项任务是合并相同的数据篮,使得患者的每个主实体有且只有1条记录。EMR可能会重复提及同一个主实体的不同细节,例如可能会2次提及相似的暴露名称,且第2次提及的内容可能包含更多有关剂量和频率的细节。不同数据篮合并不能仅依靠主实体标准代码和医疗报告ID的匹配,例如左眼眼压检查和右眼眼压检查的数据篮无法合并。因此,需要为每个主要的数据域(域标签)分别编写规则。只有检查名称(主实体)和位置实体(属性实体)以及医疗报告ID都匹配才能合并数据篮。数据篮的合并可能出现以下4种情况:①信息不足:是指数据篮无法体现其唯一性。②不同身份信息:是指在有支持不同数据篮合并的属性实体。③冲突信息:是指可以对数据篮进行合并但有些数据互相冲突。④可确认信息:是指可合并的数据篮间的数据存在不同但不属于冲突。以上4种情况中,只有可确认信息和不同身份信息下的数据篮能够合并,并生成最终的事实表。事实表由事实ID、主要实体ID、主要实体标准标签类型、实体ID、实体标签类型、实体标准值和跟踪数据(医疗报告ID和章节文本位置)的元素组成。最后,事实表中根据主要实体标准标签类型和实体标签类型映射到适当的CDISC CDASH数据元素中,用于CRF表的预填充。
04、讨 论
4.1 互操作性方面的注意事项
改进系统间的互操作性是实现RWD标准化的关键。从既往研究的经验来看,确保各系统间传达数据的意义一致的同时简化审核过程,就可以实现互操作性。
在本研究中,EMR和EDC系统通过元数据标准(如HL7 CDA和CDISC ODM)传递数据。现阶段最大的障碍是医院病历系统供应商早在制定行业标准之前就建立了自己的系统,导致缺乏可用于数据交换的标准。在我国,虽然监管机构一直致力于推进医院数据互联互通,通过对医院数据共享能力进行评级等方式,以期提高其运用标准[17]。但由于医院间数据共享活动并不活跃,HL7 CDA标准尚未得到广泛应用。另一方面,CDISC ODM在EDC系统中作为表示CRF的方式得到了很好的实现,但由于缺乏要求,可能会偏离CDASH标准命名方法对其数据字段的严格使用。ESR平台已考虑到这些限制,特别是对于EMR数据,通过标记和提取每个报告中的章节完成基本文档的结构化,建立EMR文档所需要的标准HL7形式的元数据。在本研究中,不需要对CDISC ODM文件进一步标准化,但未来希望可以通过NLP使用CDASH标准对未标准化的CRF进行注释。
为了确认数据意义是否准确、是否能被研究团队理解,本研究关注了使CRC能够方便审核每个CRF表格、提供可视化的溯源界面、能简单在电子文件上签字并发送回EDC系统。因为系统记录了整个数据标准化过程,可追溯性可以通过ESR平台得到保证,并允许CRC为每个CRF字段显示是从临床文档中何处提取的。目前,本课题组正在致力于通过将临床研究助理(CRA)和数据管理者(DM)的质疑传回ESR系统,以使研究团队能够对源数据或填充的数据提出疑问,从而更好地简化数据审核流程。
4.2 临床研究数据建模注意事项
在研究标签的开发过程中,通过对主要实体(域名)进行分类以及重复利用属性实体来减少标签数量。采用这种简单模型能使NLP在提取临床文档实体时更加高效。主要实体(域名)使用定义更广泛的分类不仅增加了标签的通用性,也可通过研究专用术语库保留原始提取术语值的特异性,以确保不会丢失原始重要信息。未来还可以从观测指标标识符逻辑命名与编码系统(LOINC)和临床医学系统术语(SNOMED-CT)等术语系统中学习更多关于不同领域数据辨认实体独特属性的方法。由于ICD-11等标准术语的较新版本通过选择多个属性来识别独特的领域概念,因此,也有利于未来识别标准术语代码的方法。
为了使本模型可在未来研究中得到推广,需要根据给定的数据收集要求和临床研究工作流程自动生成一个简单标注模型。《CDISC治疗类别数据标准化指南》[18](CDISC Therapeutic Area Guideline)在总结给定治疗领域的数据收集工作流程方面表现较好,可用于指导仅根据数据要求为每个治疗领域自动创建的简单模型。与将标注模型迭代聚合为更大模型的方法相比,创建简单模型能避免数据生成和NLP训练过程中的复杂性。此外,简单模型更容易应用于实际研究,并能够向研究人员解释数据标准化的过程,而不是形成难以解释的黑盒。未来的目标是进一步评估这些简单模型在何种程度上可以推广到其他临床研究领域。
4.3 数据规范化推理注意事项
为了对临床文档中提取的实体进行适当的推断,本研究采取的措施是提高源数据的完整性,并应用一定的推断规则确保记录的唯一性。本方法的优势是能够预先与研究人员在填写EMR前进行协商,促进EMR书写的简洁性和完整性,实现高质高效的数据提取。前瞻性数据收集的优势在于能够以最佳方式指导研究人员记录数据。此外,研究发现,如果相关实体之间距离太远,通常无法很好地提取实体之间的关系。提取实体和实体关系后,需要使用推理规则形成患者主实体数据的唯一记录。网络分析通过分析实体间关系来捕获数据之间的潜在关系,以完整地合并收集数据中的详细信息。本研究提出的具体方法是先找到主实体之间的链接,在对主实体是否一致进行推断的基础上,判断是否能将详细信息(属性实体)合并。为了确保主实体的一致性,提取的实体首先必须使用研究特定术语库注释标准代码。目前,在研究专用术语库的开发过程中,可能存在无法与较粗糙的标准术语字典(如ICD-10)充分匹配的现象,建议未来使用更全面的术语库,如统一医学语言系统(UMLS)[19]。然而,UMLS尚未较好地汉化,但OMAHA组织目前正在努力使用类似UMLS的方法建立一个综合性的术语库,以满足术语标准化的需求[19]。一旦涉及实体间关系的分析,就需要应用规范化规则来辨认数据的唯一性质。优化主实体唯一性质及相关属性的推断需要进行更广泛的讨论,可能需要开发一种联合算法,例如结合网络分析及机械学习的方案。规范化规则的优化对于未来临床决策支持系统的开发具有重大作用,但也必须先从可靠与简洁的源数据标准化工作开始。

来源:中国食品药品监管杂志


