嵌入式硬件专家瑞萨电子宣布推出首款基于免费开放的 RISC-V 指令集架构 (ISA) 的完全自主研发的处理器内核。
众所周知,在过去,该公司已经推出了采用晶心科技RISC-V内核的产品,如32位语音控制ASSP、电机控制ASSP和64位通用微处理器“RZ/Five”,但它还没有利用通过这项技术,该公司计划提高其在 RISC-V 市场的地位。
瑞萨电子的 Giancarlo Parodi 在谈到该技术时表示:“RISC-V ISA 在半导体行业中的日益普及是创新的福音。它为设计人员提供了前所未有的灵活性,并将缓慢而稳定地挑战和改变嵌入式系统的当前格局。”该公司最新的微控制器的背后。“过去,瑞萨电子已经采用了 RISC-V 技术,引入了基于 Andes Technology Corp 开发的 CPU 内核构建的用于语音控制和电机控制的 32 位 ASSP 器件。令人兴奋的下一步是[我们的]首款内置 -内部设计的 CPU 核心。
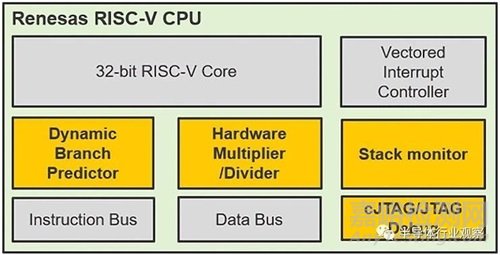
虽然瑞萨电子尚未透露将使用其内部核心的部件的完整产品细节,但它已经确认了有关核心本身的一些技术细节。框图显示了单个 32 位 RISC-V 内核,具有性能提升的动态分支预测器、硬件乘法器/除法器、向量中断控制器、堆栈监视器寄存器、独立的指令和数据总线以及紧凑型 JTAG (cJTAG)/ JTAG 调试功能。它还承诺 3.27 CoreMark/MHz)的性能水平——尽管时钟速度尚不清楚。
“该 CPU 适用于许多不同的应用环境。它可以用作主 CPU 或管理片上子系统,甚至嵌入到专门的 ASSP [特定应用标准产品] 设备中,”Parodi 声称。“显然它非常灵活。其次,在硅片面积方面,该实施非常高效,除了对成本影响较小的明显效果之外,还有助于降低待机期间的工作电流和漏电流。第三,尽管针对小型嵌入式系统,但它提供了令人惊讶的高水平计算吞吐量,甚至可以满足深度嵌入式应用日益苛刻的性能要求。”
该核心利用免费开放的 RISC-V 指令集架构及其多个扩展:Parodi 表示,该核心实现了带有乘法 (M)、原子访问 (A)、压缩指令 (C) 的 RV32I 或 RV32E ISA ,以及位操作 (B) 扩展。Parodi 声称:“这就是 RISC-V ISA 概念的美妙之处,它是从头开始构建的,允许设计人员根据目标用例选择要包含在处理器中的元素,并最终优化由此产生的功耗、性能和芯片占用空间之间的权衡。”
瑞萨电子表示,目前正在向“精选客户”提供带有新内核的芯片样品,首批商用芯片将于明年第一季度推出。
RISC-V 的核心:新视野
RISC-V ISA 在半导体行业中的日益普及是创新的福音。它为设计人员提供了前所未有的灵活性,并将缓慢而稳定地挑战和改变嵌入式系统的当前格局。过去,瑞萨电子曾采用 RISC-V 技术,推出基于晶心科技开发的 CPU 内核的 32 位 ASSP 设备,用于语音控制和电机控制。
令人兴奋的下一步是第一个内部设计的 CPU 内核的推出。
但它有什么特别之处呢?首先,该CPU适用于许多不同的应用环境。它可以用作主 CPU 或管理片上子系统,甚至嵌入到专用 ASSP 设备中。显然它非常灵活。其次,该实施方案在硅面积方面非常高效,除了成本影响较小的明显效果外,还有助于降低待机期间的工作电流和漏电流。第三,尽管它针对的是小型嵌入式系统,但它提供了令人惊讶的高水平计算吞吐量,甚至可以满足深度嵌入式应用日益苛刻的性能要求。
在此基础上,实施者可以在 RV32“I”或“E”选项之间进行选择,以优化通用寄存器的可用数量。例如,在小型子系统不需要处理复杂的堆栈和应用程序但专用于服务特定外围设备或执行内务任务的情况下。
RISC-V ISA 还预见了几种“扩展”,它们以比使用标准强制 ISA 更好或更有效的方式实现特定功能。瑞萨电子选择整合其中的几个:
M扩展– 加速并优化乘法(和除法)运算,利用硬件乘法器和除法器单元实现最快的指令执行;
A扩展– 支持原子访问指令,可作为并发和独占访问管理的基础(通常在基于 RTOS 的系统中);
C 扩展– 定义仅以 16 位编码的压缩指令,特别有趣,因为它们可以轻松地为常见和频繁指令节省内存空间,从而允许编译器在可能的情况下选择这些优化;一个简单的技巧,可以缩小代码并同时提高性能;
B 扩展– 添加了多个位操作指令,这对于基于位域编码值管理外设寄存器、协议和数据结构的应用程序来说具有位优势,其中一组组成的通用指令的功能通常可以由单个专用指令代替;
这就是 RISC-V ISA 概念的美妙之处,它是从头开始构建的,允许设计人员根据其目标用例选择要包含在处理器中的元素,从而优化由此产生的功耗、性能和芯片占用空间。从工程角度来看,这是一种非常优雅的方式,可以确保您只为那些您真正想要实现的事情“付出代价”。
为了增强应用软件的鲁棒性,添加了堆栈监控寄存器。这对于检测和防止堆栈内存溢出非常有用,这是非常常见的问题,但有时很难仅通过测试覆盖率来发现。由于这些问题可能会损害系统的完整性并在运行时产生应用程序错误行为,因此这是一个非常好的功能,也是控制此类不可预见事件的基本安全网。
即使是最简单的控制系统通常也必须管理多个决策路径来为应用程序提供服务并随时调用适当的处理例程。或者对数据缓冲区反复执行一些重复计算。因此,实现的代码将具有多个分支、循环和决策点,其中程序流程可能会根据上下文而改变。由于这种模式很常见,CPU 还具有动态分支预测单元,以使此类处理更加高效。分支预测器的作用是观察代码行为,然后动态推断在此类控制循环期间最有可能执行的下一条指令。如果我们假设它在这方面做得很好,那么在选择下一条要获取执行的指令时做出正确的猜测,它将显着提高平均代码执行吞吐量。
下一个要提到的构建块与调试功能有关。除了标准Jtag外,CPU还支持两线紧凑型Jtag调试接口,非常适合用户应用引脚数量有限的最小微控制器封装。CPU 中还实现了多个性能监视器寄存器,从而可以轻松地对所执行代码的运行时行为进行基准测试。
任何嵌入式系统的另一个关键因素是对事件的响应能力,在微控制器级别的深度嵌入式设备中,硬实时行为是强制要求的,这意味着应用程序有有限的时间来响应特定事件。低响应延迟可以带来许多不同的好处:允许应用程序为更多并发事件提供服务,提供合理的时间裕度以确保正确的任务处理,或者可能限制 CPU 速度以节省更多电量。
在架构层面,瑞萨电子的实现添加了寄存器组保存功能,以改善延迟并使开发人员能够享受其优势。在中断服务的情况下,或者当嵌入式 RTOS 必须交换当前执行的线程以响应事件时,可以备份和恢复 CPU 工作寄存器并加速上下文切换,举两个几乎直接的例子。
为了进一步帮助开发人员对应用程序进行基准测试并验证其行为,还可以使用高效且紧凑的指令跟踪单元,该单元可以进一步深入了解系统的运行时行为。
这概述了有关 CPU 功能的详细信息,其中一些功能可以根据应用和市场要求进行选择。但是,在评估和制造基于这种新技术的实际产品时,还应该考虑什么?首先,所需的工具链可作为开发和部署解决方案所需基础设施的一部分。客户将能够受益于带有配置插件的 Renesas e 2 studio 环境或任何支持基于 RISC-V 的 MCU 的主要商业第三方 IDE。这些都可以使用了。
其次,CPU 实现不仅仅是模拟的,其功能已经在真实的硅产品实现中进行了设计和验证。使用基于 LLVM 的开源编译器工具链时,初始基准测试显示出令人印象深刻的 3.27 CoreMark/MHz 性能,优于市场上的同类架构。一旦第一个产品于 2024 年初推出,有关这一优异成绩的更多详细信息将在EEMBC 网站上找到。正如许多人所指出的,专有商业编译器的性能一旦经过验证,预计将比初步结果更高。
这款新 CPU 是后续步骤的基石,为现有瑞萨 MCU 产品组合创建了一个额外的补充选项。瑞萨电子已准备好为客户提供最广泛的解决方案,其中包括不断发展的创新 RISC-V 架构。
原文链接:https://www.renesas.com/us/en/blogs/risc-v-core-new-horizons