您当前的位置:检测资讯 > 科研开发
嘉峪检测网 2021-07-17 22:48
尽管人工智能(Artificial intelligence, AI)对图像识别等领域产生了深远的影响,但在药物发现方面仍处于起步阶段,目前主要集中在给定化合物的类似物识别,构效关系(Structure-Activity Relationship, SAR)分析,部分物理化学性质的预测上等。
然而,在面对传统技术难以突破的难靶先导化合物发现及多维的成药性决策上仍突破很少,尤其是在First-in-class功能化合物发现和体内功效方面,尚未能完全发挥AI在药物研发中的潜力。因此,选择药物研发中什么样的科学问题以及要对哪些成药指标进行建模将是在药物研发中发挥AI突破的关键。
20世纪80年代以来,来源于化学计量学和计算机科学的算法逐步应用并扩展到药物的合成与分析,如基于结构的药物设计(Computer-Aided Drug Design, CADD),常用于解释药物化学结构变化与活性的关系的构效关系;定性/定量机器学习方法(Machine Learning, ML),对水溶性、代谢性、毒性等进行预测。
随着生物信息学的不断发展,其技术也在不断与药物研发中用到的算法相比较并互相融入。药学是一个融合化学和生物学的学科,在数据层面,我们首先看一下来自化学和生物领域数据的差异:
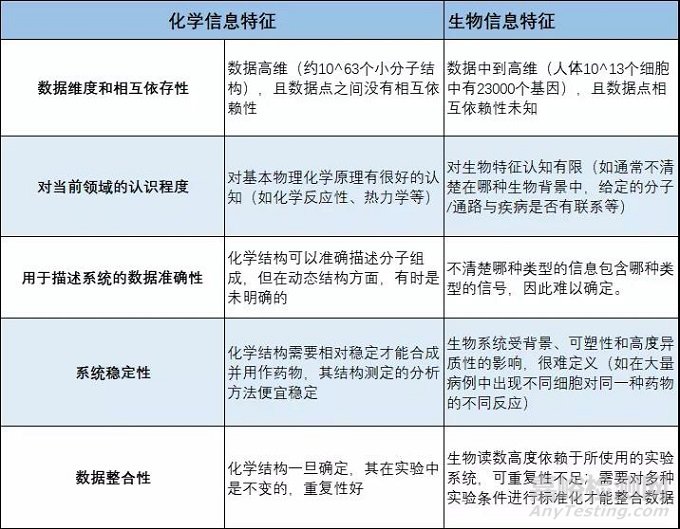
如上所示,当前化学信息显然比生物学信息可适合进行人工智能计算处理。物理化学中热力学基本原则可以在一定程度上明确配体对受体的亲和力。
与之相比,在生物学中受体蛋白的构象变化,平衡和偏置信号就难以定量;当研究涉及到基因表达量或蛋白质修饰的变化时,会变得更加困难,因为建模涉及了对空间变化和时间变化进行模拟。
当前一些药物发现的辅助细分领域中,我们能够很好地描述化学数据,并且有大量可用于模型建立的测定数据(如小分子的各种体外物理化学性质和晶型),这些也是当前AI可以发挥作用的地方。
但是在真实药物的核心研发步骤中,对于小分子药物在生物系统中的作用很难用一组有限的参数来定义,使得人工智能在药物发现和药效评估上面临着更大的不确定性。
简而言之,药物研发中开展AI需要可以定量的变量和有意义的标记。但是在特定的生物靶标体系中,我们常常无法确定哪些是重要的变量,难以通过实验对其进行定义并获得数据,也无法在与AI兼容的水平上构建体现生物学功能的参数。在此,我们对当前药物研发中数据的AI利用进行一些回顾和反思。
药物发现中,质量决策比速度和成本更重要
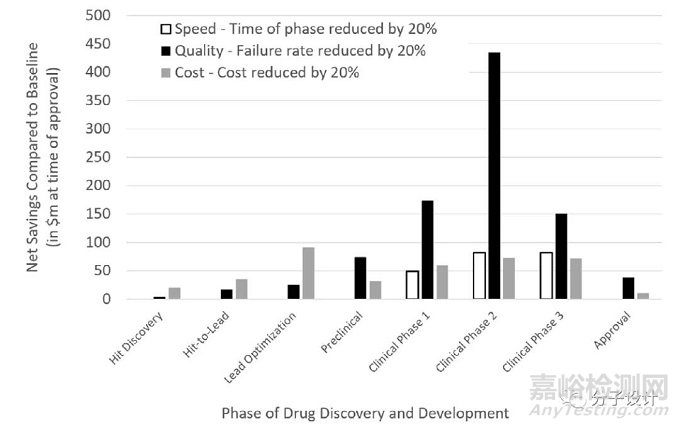
考虑到一个专利寿命为20年,假设在临床一期开始时提交专利申请,为了项目平均能够覆盖成本,我们比较了提高化合物的发现速度(每一阶段花费时间减少20%)、提高化合物的成药质量(每一阶段故障率减少20%)和降低化合物成本(减少20%)对药物发现项目净利润的影响(如上图)。
可以看出,化合物质量对项目的成功有更深远的影响,远远超出了提高各自阶段的提高速度和降低成本。降低由于化合物质量带来的损失对项目价值的总体影响最大,远比提高化合物发现及推进速度重要。换句话说,提高化合物的药物成功率可减少将药物推向市场所需的试验次数,而失败次数的减少比更快或较少花费的失败更为重要。
这一分析结果对于AI在药物发现中的应用有着重要意义。原则上,AI可以实现以上所有目标:可以更快地做出决策(预测要比实验快)并且可以更便宜地进行决策(预测的成本要低于实验),并可以做出更好的决策(在合适的数据或模拟允许的情况下,以及如果有事实支持,决策会更好)。
然而,目前人工智能在药物发现中的主要重点似乎是加快速度和节省成本,而不是决策化合物的质量或是对药效成功的影响。那么在AI药物研发中,应该如何定义化合物质量的成功?为了使AI在药物发现项目中显示其价值,这一关注点可能需要进一步明确,模型构建不应局限于加快每一阶段的速度和节省成本。
当前处于各自孤立机制和靶标中使用的AI发展困境
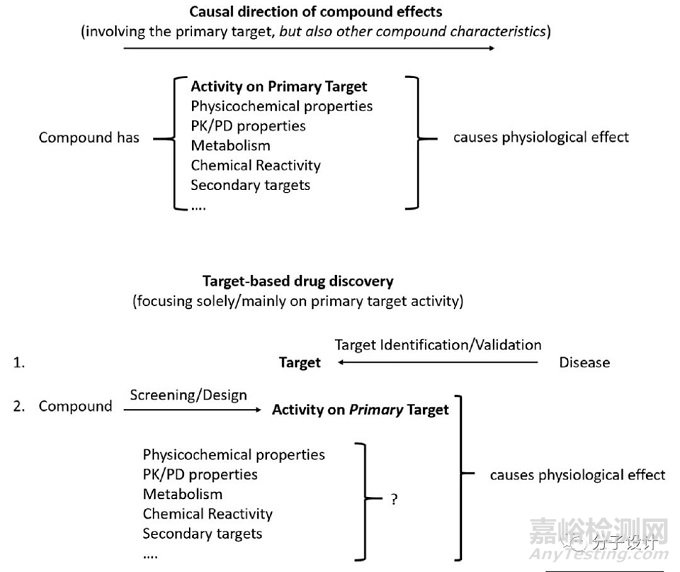
如上图所示,化合物可以通过调节蛋白质活性来实现它们的效果,但这一过程会受到药物代谢、药物活性以及非靶点效应等多重因素影响。
在目前AI方法面向的药物发现中,其主要关注点是化合物对蛋白质的活性,而化合物在体内的其他特性(包括其前体化合物,代谢产物,浓度依赖性效应等)则在模型中被降级为次要的或可忽略部分。
由于AI模型从一开始就很少考虑生物学的复杂性,使得这种模型方案在实际应用存在多个问题而降低成功率:
▨ 仅在单因果疾病的情况下才是合理的,如在病毒感染的情况下,某种蛋白酶是复制或者受体进入细胞所必要的。基于这类单一靶点确实有效并且已经产生了大量的批准药物。但是,更多较复杂的疾病难以靠单一靶点调控进行有效修复,导致了许多基于单一靶点药物在临床实验中失败。
▨ 在AI系统中往往会简化模型而忽视其他问题,如化合物是否到达其预期的靶点,是否能够治疗患病的表型,以及它的副作用是否在可以接受的范围。
▨ AI系统要取得成功,需要建立明确的“化合物-靶点-表型”联系,这是在当前生物医学知识下非常困难的。
药物发现中相关的化学和生物数据特征及其未来可扩展空间
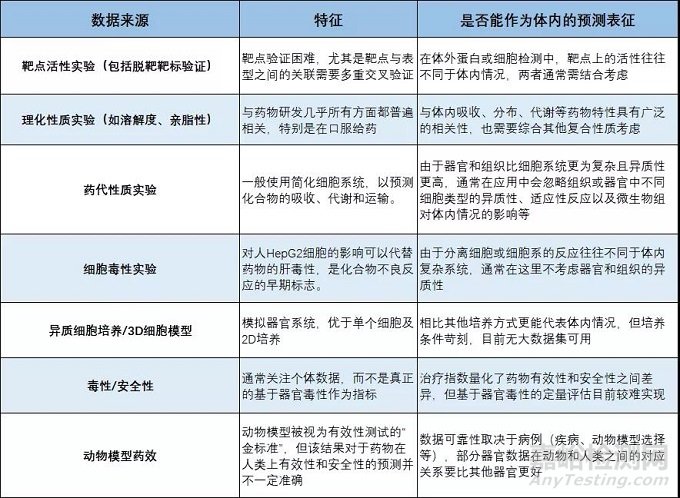
如上表所示,当前药物发现项目中使用的代表性指标。大部分并不能很好地表征人体体内的实际情况。
近年来,出现了一些来源于临床相关模型的高通量数据,例如用于高通量测试的异质细胞系统及其参数(3D中的细胞间相互作用和渗透性)和患者衍生的测试系统(癌症中患者衍生PDX模型)。
这些系统产生的数据将来可能会对药物发现产生重大影响;但当前阶段,可用于AI挖掘的数据仍相对较少,需要生成足够大量的数据才能真正实用。
人工智能在药物发现中的未来展望
为了充分发挥人工智能在药物发现中的作用,我们需要提高针对靶点发现的化合物质量。但在多数情况下,可用于做出这些决定的数据并不完全适合这一目的。
因此,我们未来需要更多的高质量化合物数据进行AI研究,包括这些化合物的体外活性/毒性指数,正确剂量/药代动力学数据等。
在后期阶段,还需要这些化合物的动物模型药效和毒性数据。此外,我们还需要更有效地进行临床试验,以获得高质量化合物临床数据。
尽管药物发现中的AI领域最近受到了广泛关注,但是利用我们当前的数据生成和利用方式,我们不太可能实现使高质量的药物发现决策。
虽然化学数据可大规模获得,并已成功用于配体设计和合成,但是这些数据并不能满足AI药物发现的需求。为了真正推动该领域的发展,我们需要更好地了解生物学,并以假设驱动的方式生成包含感兴趣信号的数据,这些信号与疗效和毒性均相关。
换句话说,我们需要让更多高质量候选化合物进入临床,更好地验证靶点,改善患者招募并更好地推进临床试验的进行,所有这些方面都是为了生成更恰当地反映药物发现生物学方面的数据。只有当这些数据可用于AI方法,才能期望该领域取得真正的进展。
参考文献
1. LeCun, Y. et al. (2015) Deep learning. Nature 521, 436–444
2. Griffen, E.J. et al. (2020) Chemists: AI is here, unite to get the benefits. J. Med. Chem. 63, 8695–8704
3. Bender A. et al. (2020) Artificial intelligence in drug discovery: what is realistic, what are illusions? Part 1: Ways to make an impact, and why we are not there yet. Drug Discov Today. doi: 10.1016/j.drudis.2020.12.009.

来源:分子设计


