本次笔记主要记录学习的几个因子设计的特殊案例,主要是无中心点的完全析因设计,包含离散变量的析因设计和包含区组的析因设计。
1. 无中心点的完全析因设计
虽然完全析因设计加中心点的方法非常有效,但是有些时候进行中心点的实验很困难或者很麻烦,不希望进行中心点的实验;有些时候实验中含有离散型因子,根本就没有中心点,虽然可以考虑选择使用伪中心点(即选择离散型因子的任意组合作为中心点),但也可以选择放弃伪中心点。
解决此问题的方法之一是,可以在因子点上进行仿行(也就是完全重复),这种解决方法的实验设计,其分析与含有中心点的实验设计完全相同。
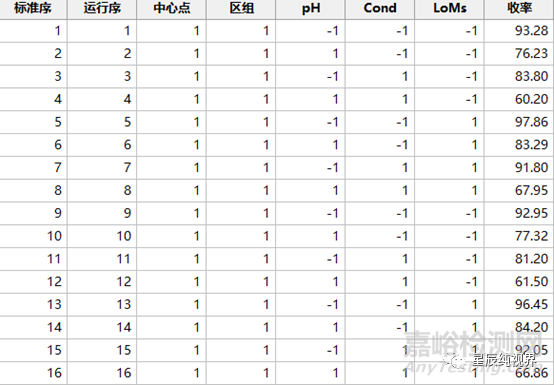
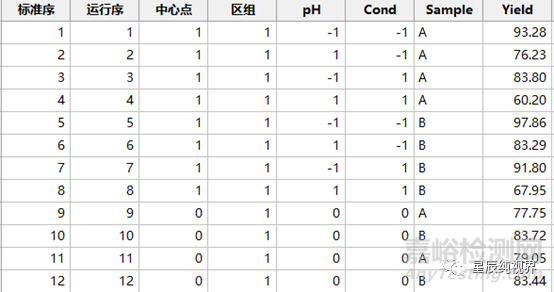
案例-1:我们设计一个阴离子流穿模式纯化单抗的案例,因子选择样品pH(pH),样品电导(Cond)和上样载量(LoMs),响应则选择为收率,设计一个3因子2水平的完全析因设计,但是不含有中心点,在角点上选择仿行2次,即因子点完全重复。实验运行表和结果如下:
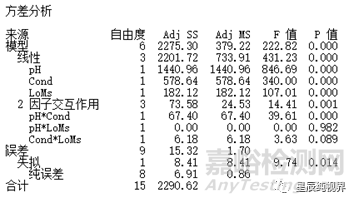
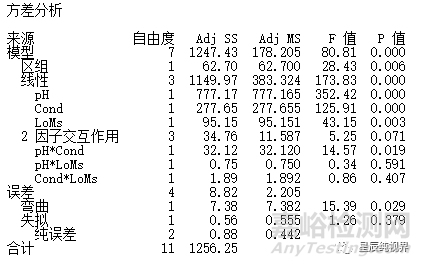
不含中心点的实验结果的分析过程与(2K加中心点)的完全析因设计的分析过程完全相同。只不过,由于不含有中心点,在分析结果的时候无法估计出弯曲效应,在误差项中只包含失拟项和纯误差项。除此之外,得到的结果也完全相同,如下表的ANOVA表。
由于不能估计弯曲效应,因此,在设计实验之前一定要考虑清楚。如果事先可以肯定不存在弯曲,那么不安排中心点则没有任何问题,如果不能肯定是否存在弯曲的话,还是建议安排中心点的实验。其余的结果分析过程从略,可参考DoE学习笔记5:完全析因设计。
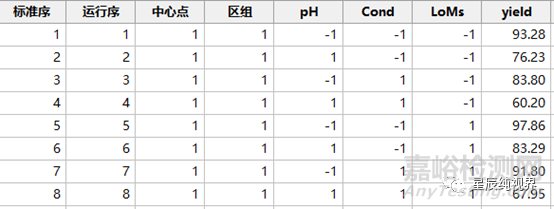
解决此问题的方法之二是,直接省略中心点实验,以剩余的因子实验的数据进行分析。先看案例,将案例-1中的8次重复实验去掉,只进行其中的8次因子实验。
我们对结果进行分析,拟合一个包含主效应和二阶交互效应的全模型,得到的ANOVA分析表如下:
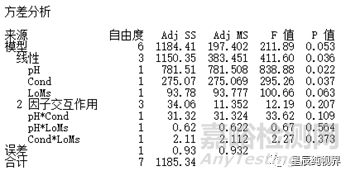
因为没有中心点,所以误差项中没有弯曲的检测,同样,因为没有完全重复实验,误差项中也缺失了纯误差的项。现在ANOVA中的误差项仅仅包含了失拟项(也就是舍弃的三阶交互效应)。以失拟项作为误差对其他的效应项进行检验。所以,该类实验中是不可能存在失拟检测的。
另外,如果模型中也包含三阶交互效应的话,那么该ANOVA中就无法再对各主效应和交互效应进行检验,因为此时已经没有了误差项(大家可自行用软件分析测试)。
相比解决方法1,这个方法虽然实验次数要少,但是在效应的检验上准确率已经大大降低,星辰君的个人建议,当因子数比较多,能够有较多的高阶交互效应存在时,可以尝试该方法。因子数为2个或者3个时,最好的方法还是设置完全重复或者中心点完全重复。
2. 含有离散型因子的完全析因设计
前面所举的例子中,所有的自变量全部为连续型的,但是实际的工作中也可能出现离散型因子,即离散型自变量的情况。
比如,我们将上述案例-1中的上样载量改变为样品A和样品B,响应变量依然为收率,设计4次中心点重复实验(样品A和样品B各两次),实验运行表和结果如下:
按照正常的完全析因设计的数据分析过程进行分析。
我们依然可以进行正常的ANOVA分析,并且可以判断模型,失拟和完全是否显著,还可以判定各项效应和交互效应是否显著。可以根据ANOVA表的结果,将不显著的效应项在拟合回归模型中予以删除。
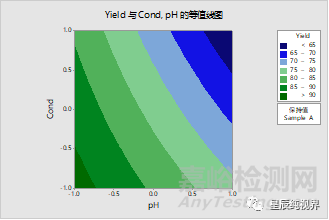
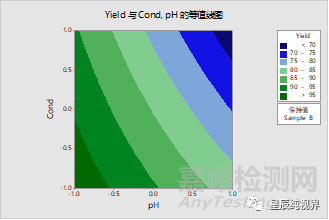
但是,含有离散变量的回归方程的解读与全部都是连续型变量的情况是不同的。虽然,DoE的分析也能给出一个回归方程,但是却不是精确的。含有离散变量回归方程一定是分叉的,或者说分情况的。
含离散变量的回归方程,可以使用Minitab的回归功能来获得,“统计>回归>回归>拟合回归模型”,上述案例拟合的回归模型为:
其余的分析也类似,可以得到离散变量取不同值的等值线图。
3. 带有区组的完全析因设计
如前面我们所述 在选择因子的时候,总会有一些因子很大可能上会对响应变量有着显著性影响,但是目前阶段我们对这些因子并不感兴趣,比如研发早期细胞培养部门给过来的不同批次来料,不同厂家提供的层析填料等等。这一类因子我们成为讨厌因子。
如果我们的实验设计中包含了这一类的因子,在实验设计分析阶段,如果不考虑这种讨厌因子的效应,那么实际的实验随机误差就会增大,在进行ANOVA分析或者因子效应显著性检验时,由于分母(误差项)变大,而常常不能敏锐的发现已经有显著效应的主效应项或者交互效应项。
解决方法是,我们可以利用区组将讨厌因子的效应分离出来,也就是:
SS误差 = SS区组 + SS剩余误差
把误差项进一步分解为“区组”部分和“剩余误差”两部分。在进行ANOVA分析或者因子效应显著性检验时,将分母限定为“剩余误差”部分,这样就可以敏锐的发现已经有显著效应的主效应项或者交互效应项,提高实验的精度。
从上面的分解来看,这种含有区组的实验设计,本质上是将“区组”当成了一个“因子”来处理了,但是它与普通的因子还是不一样的,我们对研究因子的效应时感兴趣的,对区组的效应则是不感兴趣的,这也是为什么把它们称为讨厌因子的原因。
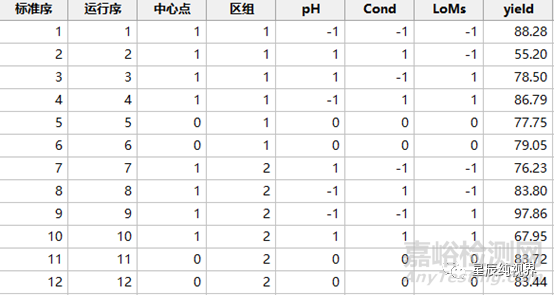
我们依然以案例-1的变化为例,因子设置样品pH,样品Cond和上样载量LoMs,同时因为有两批次的样品,Sample A和Sample B,我们将样品设置为两个区组,设置4个中心点实验,每个区组含有两个中心点实验。实验设计表和结果如下:
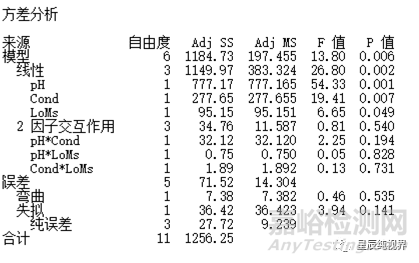
对含有区组的因子设计进行分析时,一定要在分析时将“区组”选为因子,即勾选“在模型中包含区组”的选项,得到的ANOVA如下:
可以看出,模型是显著的,失拟是不显著的,弯曲效应是显著的(这个需要后续继续分析,包括残差的诊断)。同时,也可以看到区组效应是显著的,即两批次的样品确实有显著性差异。
对各效应项进行分析,发现依然pH*LoMs和Cond*LoMs是不显著的。可以在后续的模型构建中予以删除。
如果在模型中不包含区组呢?会出现什么情况呢?
通过两个ANOVA表对比,如果模型中不包含区组,pH*Cond也开始变得不显著,同时弯曲效应检测也不显著了。这就是因为显著的“区组”效应被添加到“纯误差”中,即误差项中。检验的分母增加,就是导致效应的显著性变得不敏感。
总之,将区组剥离,纳入模型中,检验因子效应的估计精度大大提高。
如果区组效应显著,在构建回归方程时,可以按照包含离散变量的回归方程构建方式来进行构建,并进行后续的分析。
区组显著,是给我们的一个很大的警示,一定要思考为什么会有这样的显著差异?要尽量的去分析原因,以便对误差进行分析。如果实在找不出原因,只能承认实验误差太大,对预测时候的结果要有心理准备,应该以较大的波动为前提进行预测。