摘 要 / Abstract
随机对照盲法临床试验用于评价疫苗安全性与有效性是公认的金标准,但由于其设计上的严苛,使得疫苗上市后,在大规模应用场景下的疫苗真实保护效果与临床试验获得的保护效力往往存在偏差,疫苗真实世界研究在此基础上被提出。新冠病毒疫苗真实世界研究被大量报道,其结果被各国采用,及时优化疫苗免疫策略。本文概括了常见的疫苗真实世界研究设计,并着重介绍了近些年发展出来的解决真实世界研究中混杂偏倚的统计方法 :倾向评分和工具变量。
Randomized controlled double-blind clinical trials are widely recognized as the gold standard for evaluating the safety and efficacy of vaccines. However, due to their rigorous design, a deviation often exists between the protection efficacy obtained in large-scale vaccine applications in real-world scenarios and the efficacy observed in clinical trials. Real world studies of vaccines have been proposed to address this issue. The real world study on COVID-19 vaccines, in particular, has been widely reported, and its results have been adopted by various countries to optimize vaccine immunization strategies. This article summarizes common designs for real world vaccine studies and focuses on recent statistical methods developed to address confounding bias in real world studies: propensity score and instrumental variable.
关 键 词 / Key words
疫苗;保护效果;真实世界研究;统计方法;倾向评分;工具变量
vaccine; protection effectiveness; real world study; statistical methods; propensity score; instrumental variable
随机对照试验通过随机化分组,能够最大限度地减少有效性估计过程中的偏倚与混杂影响,保证了可靠性。但其有局限性:(1)试验人群的高度选择性,在研究结论外推时面临挑战,如新冠病毒疫苗在孕妇人群的使用;(2)对于发病率低的罕见病等疾病,试验难以实施。1993年,Kaplan等[1]在雷米普利治疗高血压病疗效的前瞻性研究中首次提出了“真实世界研究(real world study,RWS)”的概念。2016年,美国颁布了《21世纪治愈法案》(21st Century Cures Act),提出了开展真实世界研究的方法,以及由此产生的真实世界证据(real world evidence,RWE)在药物开发中的应用。目前,对于真实世界研究定义的共识是指针对预设的临床问题,采用预设的研究设计,在真实世界环境下按照研究方案系统性收集与研究对象健康有关的原始数据(真实世界数据,real world data,RWD)或基于常规产生的二手数据进行分析,获得临床证据(RWE)的研究过程。概括地说,真实世界研究就是基于科学的设计,收集分析RWD,形成RWE的研究[2]。
真实世界研究的流行病学方法学进展不大,常见的有队列研究(cohort study)、病例对照研究(case-control study)、家庭续发率研究(secondary attack rates in families)。队列研究由因及果,基于新发病例,能提供更多关于疾病自然史的信息以及发病率和相对风险的直接估计,能确立暴露与疾病之间的时间关系,可以研究与暴露相关疾病的多种结局[3-4];但随访时间一般相对较长,需要样本量较大,研究费用高,不适于罕见病研究。病例对照研究需要样本量较小,研究的关键是识别病例,而不是跟踪大量研究对象,因此经济、高效。但病例对照研究通常只能分析单一的感染结局;没有关于病例来源的人群信息,无法确定发病率和流行率;容易产生选择偏倚、就医行为偏倚、回忆偏差等,对疫苗保护效果的估计带来偏差。家庭续发率研究通过估计指示病例家庭中的疾病续发情况,结合疫苗免疫记录计算疫苗效果[5-6]。家庭续发率研究的优势在于可以降低研究对象间病原暴露的差异所导致的偏倚[7]。因前期的计划生育政策,国内家庭多为三口之家,给该类研究带来不便。
在新冠病毒大流行期间,一些以往不常用的观察性流行病学方法被运用到新冠病毒疫苗的效果评价中,包括检测阴性设计、实用性临床试验,以及阶梯式楔形设计。检测阴性设计在传统病例对照设计的基础上进一步发展,其中对照组人群应符合与病例组相同的临床病例定义,并通过实验室检测结果进行区分,目标病原体检测阳性者为病例组,检测阴性者为对照组,同时比较两组疫苗接种情况,估计疫苗的保护效果[8]。该设计中,病例组和对照组通常来自相同的社区或在同一医疗机构寻求治疗,减少了传统病例对照设计所涉及的不同社区间,由于疫苗获取和疾病风险的差异,以及就医行为差异造成的选择偏倚;可以利用常规监测系统,如严重急性呼吸道感染监测,经济、快速评价流感疫苗或新冠病毒疫苗的保护效果。实用性临床试验旨在评价干预措施在真实世界环境日常实践中的有效性[9],表现为对研究对象不进行严格的纳入和排除限制,具有广泛代表性,包括弱势人群[10-11];但保留研究中心层面的随机化以减少选择偏倚[12-13]。阶梯式楔形设计是指干预措施在若干时间段内按顺序随机给予不同集群,即在初始阶段,所有集群都未暴露于干预措施,随后每隔一段时间,随机将部分集群从对照组转移到干预组,最终所有的集群都暴露于干预。该设计多用于评价疫苗免疫的免疫屏障效应。
RWE源于高质量的RWD和科学的研究设计。但由于缺乏对研究个体的随机化,真实世界研究统计分析更需密切关注对混杂或偏倚的控制。不同于真实世界研究中的流行病学方法学,对于已知并可测量的混杂,统计学方法学除了配对分析、分层分析、协方差分析以及多因素分析等经典方法外,近些年还发展了一些新的统计方法,例如,对于已知并可测量混杂的倾向评分,以及对于未知或未测量混杂的工具变量。以下对真实世界研究常用统计学方法进行概述。
1、倾向评分
倾向评分作为一种分析观察性研究的方法,应用十分广泛,由Rosenbaum和Rubin于1983年在反事实理论的基础上首次提出[14]。该方法在真实世界研究中可用于均衡协变量的组间分布,各组研究对象根据评分相同或相近的原则匹配成对,保证整体各匹配组特征协变量的分布是均衡可比的。可以认为,不同组间存在的混杂因素基线的不均衡性对处理效应估计的影响被抵消了,相当于“类随机化”或“事后随机化”,从而控制组间偏倚,使得RWD达到“接近受试者随机入组”的效果。
倾向评分模型是由多个协变量共同构建的函数,是指在给定协变量的条件下,每个研究对象被划分到处理组的条件概率。假设在给定协变量的情况下,第i个研究对象被分入处理组的条件概率表示为:
e(X)=P(G=1|X)
式中,G代表组别或处理因素,其中G=1为处理组,G=0为对照组;X为协变量向量,X=x1,x2,…,xm。当研究对象i所在组别G与协变量X相互独立时,有P(G1,G2,…,Gn|X)=∏Ni=1e(X)Gi{1-e(X)}1-Gi。其中,e(X)即为倾向评分。
即,假如某个研究对象分配到处理组的倾向评分与另外一名虽然拥有不同基线特征(即不同的协变量取值)且为处理组的研究对象的倾向评分相同,则构建此倾向评分的多个协变量整体上在这两个研究对象之间是均衡的。
在估计倾向评分后,有4种研究方法可以使用该评分来控制协变量:倾向评分匹配、倾向评分分层、倾向评分协变量调整和倾向评分逆概率加权,可以提高组间的均衡性,从而减少或者消除协变量对治疗效应估计的影响[15]。
1.1 倾向评分匹配
倾向评分匹配应用最为广泛,可以将多个协变量或者混杂因素纳入模型估计每个研究对象的倾向评分。针对处理组每个个体,在对照组中匹配与该研究对象评分相同或最相近的研究对象,最终达到组间协变量整体均衡。下面介绍倾向评分匹配中最常用的匹配方法:最近邻匹配(nearest neighbor matching)和卡钳匹配(caliper matching)。
最近邻匹配是指将两组研究对象进行随机排序,从该组第一例研究对象起到最后一例,依次在对照组中选择与其倾向评分最接近的研究对象匹配,形成具有相似倾向评分的处理组和对照组匹配数据集;而卡钳匹配较最近邻匹配需增加一个限制条件,该限制条件为处理组与对照组个体用倾向评分进行匹配时,需要在事先设定的处理组和对照组倾向性得分差值范围内进行匹配,即匹配的研究对象之间的倾向评分差异最多相差此固定的卡钳值宽度。因此,设定的卡钳值大小会直接影响处理组研究对象能匹配到对照组研究对象的数量,较大的卡钳值意味着在此得分差值范围内,能够匹配到较多较相似的研究对象,匹配后的数据集样本量就越大,但相应地会降低组间协变量的均衡性;而较小的卡钳值意味着倾向评分更接近,能够匹配到更相似的研究对象,能够增加组间协变量的均衡性,但匹配成功的概率降低,最终导致匹配后数据集的样本量较小,甚至会出现处理组研究对象无法匹配到对照组研究对象的可能。Cochran等[16]研究指出,卡钳值使用两组倾向评分logit的合并标准差的60%可以消除由于测量的混杂因素所引起的86%~91%的偏倚,取倾向评分logit的合并标准差的20%至少消除98%~99%的偏倚。Austin[17]使用蒙特卡洛模拟来检验倾向评分匹配的卡钳宽度与风险差异及均值差异估计间的关系,在应用中推荐使用20%的卡钳值,或者取两组间倾向性得分绝对差值为0.02或0.03等。根据近些年的研究成果,倾向评分经过logit变换后标准差的百分比较固定值更加适宜。也有研究者对三分组研究中倾向评分匹配的卡钳值宽度进行研究,模拟结果同样显示,卡钳值取倾向评分经过logit变换后标准差的20%是比较合适的差值范围[18]。
1.2 倾向评分分层
倾向评分分层是另一种常用的方法,用于调整研究中处理组和对照组间的系统差异,是将每个研究对象的倾向评分作为分层的标准,通过模型估计倾向评分后,确定倾向评分界值的范围并划分区间,将划分好的区间作为分层因素进行分析。此时,同一分层内的基线协变量的组间分布应是均衡可比的。当各分层样本量充足时,可以对每个分层进行单独的分析,也可以对每个分层的处理效应进行权重赋值,再使用加权平均的方法估计处理效应。使用倾向评分分层进行分析的关键是合理的设定分层和权重,比较分层内倾向评分组间是否均衡是检验设定层数是否合理的方法。
1.3 倾向评分协变量调整
倾向评分协变量调整方法是将多个基线协变量纳入模型后计算的倾向评分作为最终的协变量引入模型中,将结局变量作为因变量、组别变量或者暴露因素作为自变量、由多个协变量拟合的倾向评分作为回归模型中的协变量进行建模,估计处理效应。有研究者认为,在此倾向评分作为协变量纳入模型的基础上,还需要纳入构建该倾向评分的基线协变量或者与结局或者处理效应相关的协变量[19]。协变量调整的方法纳入所有的研究对象进行分析,最大限度地保留了所有的原始数据信息,但两组之间的协变量可能不具有可比性,不能像倾向评分匹配或倾向评分分层一样控制研究中存在的偏倚,增加无效估计的可能性;但倾向评分校正是基于模型的分析,因此并不鼓励使用该方法。
1.4 倾向评分逆概率加权
倾向评分逆概率加权可以调整观察性研究中的混杂因素对结局造成的影响,通过估计每个研究对象的倾向评分,以此为基础赋值权重,然后对每个个体进行逆概率加权,估计处理效应。该方法基于一个以所有研究对象为基础的虚拟人群(合成样本)。在该样本中,观察对象的暴露分组与可测量的基线协变量相互独立,即组间可测量的协变量具有近似的分布。有研究者在应用时提出了不同的权重配置方法。一种最常用的方法是逆概率加权,观察单位的权重定义为观察单位实际接受处理组概率的倒数[18]。另一种方法是修饰逆概率加权,该方法会定义一个临界值,临界值通常根据权重分布的百分数来定义,如处理组权重分布的1%分位数,对照组权重分布的99%分位数。权重超过临界值的观察单位会被排除出估计处理效应的数据集,或将权重统一修饰为临界值[20-22]。
倾向评分主要分为以下步骤[23]:(1)根据专业意义判断,以组别变量为因变量,已知可测量的协变量作为自变量构建logistic或probit模型。(2)以现有的RWD拟合模型,估计参数。(3)估计每个研究对象的倾向评分,范围在0~1之间。(4)根据估计的倾向评分,通过倾向评分匹配或倾向评分分层等方法使纳入模型的基线协变量在各组间的分布达到均衡。(5)选择合适的统计方法评价使用倾向评分方法后基线协变量在组间分布的均衡性。(6)采用传统分析步骤对校正均衡后的RWD进行分析,估计处理效应。
2、工具变量
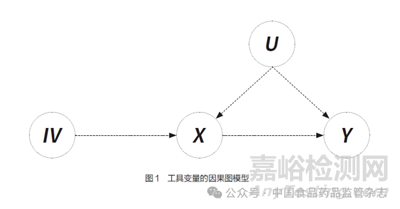
在经典回归模型中,最小二乘法成立的重要前提是解释变量(自变量)与模型误差项不相关。如果自变量与结局变量之间未测量的混杂以及逆向因果关联会使解释变量与模型的误差项相关,与经典回归模型的假设不一致,则效应估计量会出现偏倚。上述倾向评分、基于回归模型调整协变量的方法只能控制已知测量的混杂因素,不能控制未知或无法测量的混杂。工具变量由Wright于1928年首次提出,尤其适用于控制未知或无法准确测量的混杂因素,使用该方法能够有效控制未观测到的混杂,从而进行自变量与结局变量的因果推断,但不能有效地调整混杂因素或协变量[24]。其因果图模型如图1所示。
其中IV表示工具变量,X为暴露(处理因素),Y为结局,U表示X与Y之间的混杂集合,包括所有的可以测量的混杂因素和未知或不可测量的混杂因素。若某变量与暴露因素X相关,只能通过影响处理因素来影响结局变量,与暴露和结局的混杂因素不相关,则该变量可视作工具变量。
工具变量的统计学原理如下式所示,在传统最小二乘法统计模型的两侧加工具变量Z,同时取协方差。
Cov(Y,X)=Cov(β0+β1X+εi,Z)=βi Cov(X,Z)+Cov(ε,Z)
即σYZ=β1σXZ+σεZ,等式两侧除以X与Z的协方差σXZ,则σYZ/σXZ=β1+σεZ/σXZ,如σεZ=0,则σYZ/σXZ=β1。只要设法找到满足条件的一个工具变量Z,即可得到X相对Y的无偏估计的效应量β1。因此,利用工具变量可排除解释变量中与误差项相关的部分,从而得到无偏倚的因果效应估计[25]。
工具变量的方法相当于在非试验环境中模拟了一个随机试验,经过随机后,组间可比性是可预期的,与实际暴露相关,可以直接推断暴露于结局的关系,使混杂因素在组间均衡可比,即能够很好地解释暴露因素对研究结局的影响。
3、结 语
相比传统的随机对照试验(randomized controlled trial,RCT),真实世界研究的研究对象纳入排除标准更为宽松,因而更具人群代表性;干预措施更加灵活,总体上更加贴近实际情况,可以弥补RCT数据证据的不足,使研究结果适于外推,提高了外部有效性。同时,研究中也会存在较多的混杂偏倚,因此尤其要注重前期研究设计,并选择适宜的统计方法。倾向评分因易于操作、步骤明确及使用效率高等优点,在观察性研究中或者非随机化研究中使用尤为广泛,该方法在使用时也应考虑其统计效能以及应用范围,在明确可测量混杂因素的基础上,可以选择倾向评分。当混杂因素未知或者不可测量,工具变量更为合适,但工具变量较难寻找。在新冠病毒大流行期间,全球各主要监管机构,包括世界卫生组织,都以超常规的程序批准了疫苗的紧急使用。在此背景下,真实世界研究设计与统计分析在新冠病毒疫苗安全性、有效性与持久性确认,以及疫苗免疫策略的制订与调整中展示了极其重要的作用与贡献。