您当前的位置:检测资讯 > 科研开发
嘉峪检测网 2021-02-25 09:08
药物筛选指的是采用适当的方法,对可能作为药物使用的物质进行生物活性、药理作用及药用价值的评估过程。药物筛选是现代药物开发流程中检验和获取具有特定生理活性化合物的一个步骤,药物筛选的过程从本质上讲就是对化合物进行药理活性实验的过程,随着药物开发技术的发展,对新化合物的生理活性实验从早期的验证性实验,逐渐转变为筛选性实验,即所谓的药物筛选。
作为筛选,需要对不同化合物的生理活性做横向比较,因此药物筛选的实验方案需具有标准化和定量化的特点。随着组合化学和计算化学的发展,人们开始有能力在短时间内大规模合成和分离多种化合物,因而在现代新药开发流程中药物筛选逐渐成为发现先导化合物的主要途径之一。过去很多制药公司采用高通量筛选(HTS)寻找新的药物分子,但是巨大的投资却没有换来质量和数量均令人满意的新分子实体药物,HTS不成功的部分原因在于这种筛选方法自身的复杂性和极其巨大的被筛选的化合物数量,长周期、高费用极大制约了新药的开发。
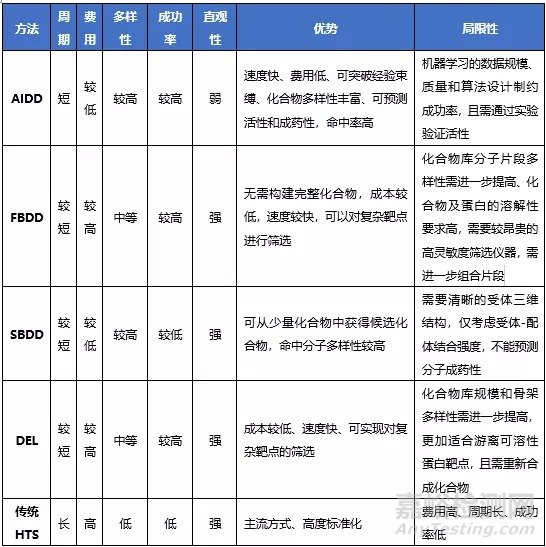
近年来众多新型药物筛选技术相继涌现,显著提高了药物发现的效率,具有代表性的有:1.基于深度学习的人工智能药物分子虚拟筛选技术(AIDD);2.基于片段分子库的筛选技术(FBDD);3.基于结构的分子设计技术(SBDD);4.DNA编码化合物库筛选技术(DEL)。
01、基于深度学习的药物分子虚拟筛选(AIDD)
过去20年,计算机处理能力的持续快速增长,大量数据集的可用性以及先进算法的开发,大大推动了机器学习的发展,由此,专注于具体任务的狭义人工智能得以实现。近十年基于人工智能的药物分子虚拟筛选方法(AIDD)层出不穷。传统AIDD算法体系下,通常使用SMILES字符串来描述分子的二维结构,再利用RNN模型(序列化深度模型)来处理SMILES数据,提取蕴含在SMILES数据中的分子特征,但这类方法的弊端有两点:1. SMILES规则对分子二维结构表征并不完备,即SMILES规则与分子二维拓扑关系并不完全一致,且引入了冗余的SMILES表征规则,以至于后续衔接学习算法时,会使算法学到SMILES表征规则而非实际的分子拓扑结构;2. RNN网络往往只能关注到有限长度的数据分布关系,超过范围的数据关系会自动丢失,因此SMILES + RNN算法仅能提取分子的局部特征(如:骨架片段或局部基团),而整体性的特征,才是分子能否成药的根本原因。
当前国际上最先进的人工智能虚拟药物筛选多是利用图卷积算法体系,其基本框架是直接从分子的二维结构出发,以原子之间的连接关系(化学键)为基础,构建基于图信息的分子表征体系,通过端到端的学习,抽取出决定分子活性以及成药性的关键信息。由于图神经网络的灵活性和可扩展性,与迁移学习、主动学习、强化学习和多任务学习等学习框架有效结合,可实现分子多目标优化及生成、小样本学习等诸多十分有前景的应用。
目前利用人工智能发现药物分子已不是新鲜事,一个非常令人兴奋的案例是麻省理工学院在没有使用人类任何先前假设的情况下,短短几天内从超过1亿个分子的库中筛选出强大的新型抗生素,其中一种抗生素可杀死多种世界上令人非常棘手的致病细菌,包括结核病和被认为无法治愈的菌株。研究人员使用一个含有2335个已知抗菌活性的分子集合来训练深度神经网络,该算法无需对药物的工作原理和化学基团进行任何标记,就可以预测分子活性。因此,该模型可以学习人类专家未知的新模式。此外,该方法还可以应用于治疗癌症、神经衰退性疾病等其他类型的药物。
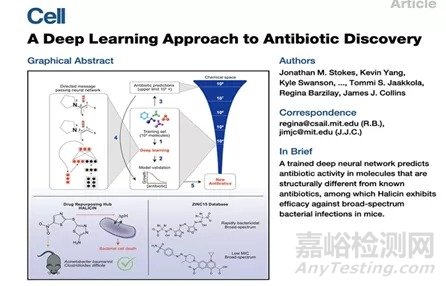
图1: 麻省理工利用深度学习技术发现超级抗生素
基于图神经网络的人工智能药物分子虚拟筛选的基本过程:首先,在已经建立的数十亿化合物分子库的基础上构建隐空间,使用成药数据集进一步训练隐空间,从而产生包含成药性信息的分子表征。其次,针对具体任务靶点采用2D和3D相似性、分子对接、药效团打分、形状及静电相似性、动力学模拟等手段筛选数十个结构新颖、活性高、成药性好的化合物用于后期化学合成及进一步实验验证,整个过程非常短,仅需3个月。
基于深度学习的人工智能药物分子虚拟筛选与传统高通量筛选相比,具有显著的优势:速度更快,3个月即可筛选出苗头化合物;采用虚拟筛选,成本更低;通过独特的分子表征模型设计,更容易筛选出活性高、结构新颖、成药性好的药物分子。但虚拟筛选同样也面临的问题,其需要大规模和高质量的数据用于对模型的训练,这直接决定了生成分子结果的质量,且生成分子后还需要合成化合物及活性、成药性验证。
02、基于化合物片段的分子筛查技术(FBDD)
基于片段的药物发现(FBDD)是最近十年来兴起的一种药物研发新技术,这一概念最早提出于1990年,与HTS相比FBDD的优势在于:1.化合物库较小;2.化合物结构简单;3.筛选到的化合物质量更好;4.效率更高;5.更具有新颖性。
FBDD的过程主要包含三个环节:1.片段库的构建;2.筛选得到可与靶点结合的片段,以及这些片段的结构构象;3.利用结构信息对片段进行优化。
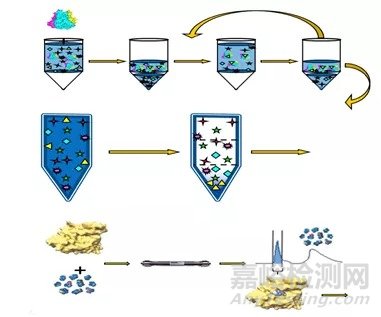
图2: FBDD主要过程
片段库构建的关键因素在于化合物库的大小,库中化合物的质量,以及检测的方法。在设计片段库时,要求片段达到以下要求:1.高溶解度;2.较高的纯度;3.不能含有活性功能团,避免片段之间的聚合;4.片段库还应充分体现结构的多样性。
筛选:FBDD发展的重要基础就是高灵敏度的筛选方法,传统的高通量筛选中所用的筛选技术不能检测到低亲和力的片段分子,而近年来NMR、X射线晶体学和一些生物物理技术的发展,为片段的筛选奠定了基础。
片段优化:通常筛选到的初始片段活性是很低的,所以筛选后的关键就在于对其加工以提高它的活性,以及改善其他性质,如选择性、成药性等。一般采用片段进化、片段连接和片段自我组装这几种方式对片段进行改造。
基于片段的药物设计正处于高速发展阶段,已涌现出许多方法,但同样面临很多挑战。首先在建库方面,目前的片段库都是对已知的药物分子进行拆分或者从商业库中根据一些性质进行选择,所以需要发展新的技术来设计和合成新片段。再次,筛选方面,靶蛋白的纯度、大小及同位素标记,片段的溶解度等这些因素一定程度上制约着筛选技术的应用。
03、基于结构的分子设计技术(SBDD)
Structure-based drug design,即基于结构的药物设计,从配体和靶点的三维结构出发,以分子识别为基础而进行的一种药物设计方法。根据药物与其作用的靶点如受体、酶、离子通道、核酸、抗原、病毒等来寻找和设计合理的药物分子。
通常SBDD的步骤包括:1.蛋白质结构准备;2.结合位点识别;3.配体库准备;4.对接和评分功能。
靶点是药物设计的先决条件,合理药物靶点的选取直接决定了药物开发的成败。靶点的三维结构,往往可以通过X-射线晶体学、多维核磁共振或同源蛋白质结构预测等计算机模型方法得到,其次利用实验手段测定或用计算方法研究药物与受体的作用模型,在此基础上来进行合理药物设计。除了考虑药物与受体的结构特点,还需要考虑药物的溶解性、毒性、代谢过程等因素的影响,合理药物设计通常需要10-15次循环的努力才有可能找到“最为合适”的药物分子。
其不足之处在于需要靶点完整清晰的三维立体结构;仅考虑药物-受体的结合强度,不能预测药物的药效,速度较慢。
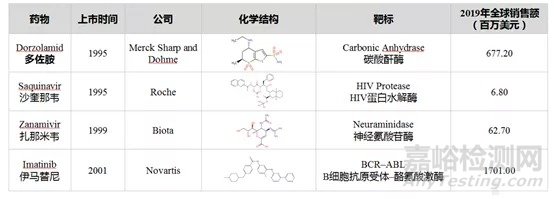
图3: 应用SBDD成功上市的药物
04、DNA编码化合物库筛选技术(DEL)
DNA编码化合物库(DNA encoding chemical library,DEL)是美国 Sydney Brenner 和RichardLerner于1992年提出并申请发明专利的一项新技术。目前,DNA编码化合物库作为新药筛选的一种强有力的工具已经越来越被制药公司及科研院所所重视。
其基本方法是将活性靶点蛋白和经DNA编码的化合物库同时孵育,亲和力强的化合物与蛋白结合,亲和力弱或不结合的化合物被除去,由于化合物与DNA编码信息一一对应,可以通过高通量测序技术得到高亲和力化合物的结构信息,重新合成不带DNA标签的化合物后进行活性验证及结构优化,从而得到苗头化合物,该方法大幅提高了新药筛选的效率。
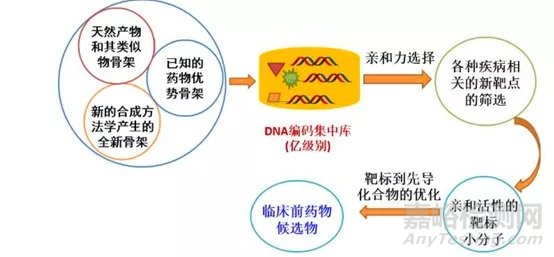
图4: DEL主要过程
DEL筛选与传统的高通量筛选方法有很大的不同。首先DEL基于亲和筛选,将纯化的重组蛋白和DEL进行共孵育,直接找到与蛋白具有结合力的苗头化合物,而传统筛选方法通过蛋白的功能变化来识别苗头化合物。其次,DEL筛选是将蛋白和整个化合物进行孵育,是数量巨大的化合物同时筛选,而非单个化合物依次筛选,这种方式具有明显的速度和成本优势。
但DEL的亲和性筛选也有需进一步完善之处,大体积的DNA编码标签有时会阻碍与目标蛋白的相互作用,一些潜在的候选物可能会丢失。此外,小分子及其DNA标记可与纯化柱结合,产生假阳性。该方法最适合于游离可溶性蛋白质,但许多潜在药物靶点在细胞表面,使得传统的亲和筛选方法无法检测它们。另一大问题仍然是要扩大分子库规模,增加化合物骨架的多样性,同时保持化合物的类药性和库的纯度。
总结:几种新型药物分子筛选方法对比
参考资料:
[1] Erlanson, D. A.; Davis, B. J.; Jahnke, W. Fragment-Based Drug Discovery: Advancing Fragments in the Absence of Crystal Structures. Cell Chemical Biology 2019, 26 (1), 9–15.
[2] Lyne, P. D. Structure-Based Virtual Screening: An Overview. Drug Discovery Today 2002, 7 (20), 1047–1055.
[3] Goodnow, R. A.; Dumelin, C. E.; Keefe, A. D. DNA-Encoded Chemistry: Enabling the Deeper Sampling of Chemical Space. Nat Rev Drug Discov 2017, 16 (2), 131–147.
[4] Stokes, J. M.; Yang, K.; Swanson, K.; Jin, W.; Cubillos-Ruiz, A.; Donghia, N. M.; MacNair, C. R.; French, S.; Carfrae, L. A.; Bloom-Ackermann, Z.; Tran, V. M.; Chiappino-Pepe, A.; Badran, A. H.; Andrews, I. W.; Chory, E. J.; Church, G. M.; Brown, E. D.; Jaakkola, T. S.; Barzilay, R.; Collins, J. J. A Deep Learning Approach to Antibiotic Discovery. Cell 2020, 180 (4), 688-702.e13.
[5] XU Li-kun,ZHANG Dong-na,DOU Yuan-yuan,SONG Ya-bin,WANG Bao-gang,WANG Hong-quan. DNA encoding chemical library in drug screening and discovery: research and application. J Int Pharm Res ,2018,45(10),736-741.
[6] 中国食品药品网,http://www.cnpharm.com.

来源:Internet


